Why Transformers?
- 텍스트 인식기를 구축의 최종 목표는 2차원 이미지를 특정 알파벳의 1차원 문자 시퀀스로 변환하는 것이다.
- “lab 02b”에서 설명한 컨볼루션 신경망은 이미지를 인코딩하여 원시 픽셀 값에서 더 의미 있는 수치 표현으로 변환하는 데 매우 효과적이다.
- 하지만 다음과 같이 고려해야 할 사안이 존재한다.
- 이미지의 글자 수를 크기와 분리하는 부분
- 문서의 스크린샷 데이터는 종이를 클로즈업한 사진보다 글자 밀도가 훨씬 높다.
- 길이가 입력 텐서의 크기와 상관없어야 하는 가변 길이의 문자 시퀀스를 어떻게 얻을 것인가?
- 이미지의 글자 수를 크기와 분리하는 부분
- 트랜스포머는 시퀀스 모델링에 탁월한 인코더-디코더 아키텍처로, 원래 기계 번역에서처럼 한 시퀀스를 다른 시퀀스로 변환하기 위해 도입되었다.
- ∴ 언어 처리에 매우 적합하다.
- 따라서 최종 아키텍처의 핵심 구성 요소로 트랜스포머를 사용해 입력 이미지를 CNN으로 인코딩한 다음, 트랜스포머를 통해 텍스트 시퀀스로 읽어낼 것이다.
- 이 새로운 모델을 사용해 보기 전에 먼저 트랜스포머 아키텍처의 역사를 살펴봄으로써 왜 트랜스포머 아키텍처가 인기를 얻게 되었는지 이해하고,
- 토이 모델과 최첨단 언어 모델의 동작을 설명하는 최근 연구를 살펴봄으로써 어떻게 작동하는지 직관적으로 파악해 보자.
Why not convolutions?
- 2016년 이전까지만 해도 자연어 처리를 위한 최고의 모델은 모두 순환 신경망(Recurrent Neural Network)이었다.
- 합성곱 신경망도 간혹 사용되었지만, 구조적 편향성이 텍스트에 맞지 않는다는 심각한 문제가 있었다.
- translation equivariance이 더 이상 유지되지 않는다.
- 텍스트의 시작 부분은 중간 부분과 상당히 다른 경우가 많기 때문에 절대적인 위치가 중요하다.
- 언어에서 지역성은 그다지 중요하지 않다.
- 수천 페이지에 등장하지 않은 캐릭터의 이름이 갑자기 등장하면 눈에 띄게 될 수 있다.
- translation equivariance이 더 이상 유지되지 않는다.
- 이미지와 달리 텍스트는 단순히 카메라를 회전하거나 번역해서 새로운 유효한 텍스트를 얻을 수 없다.
- 위치에 구애받지 않고 읽을 수 있는 책은 드물다.
- 컴퓨터 과학과 깊은 상호 영향을 주고받는 형식 언어 이론 분야에서는 컨볼루션 네트워크의 문제를 설명하는 한 가지 방법을 제시한다.
- 컨볼루션 네트워크는 모든 정보를 유한한 창 내에서 찾을 수 있는 유한한 맥락의 언어만 이해할 수 있다는 것이다.
- 컴퓨터 과학과의 연관성에 도출된 즉각적인 해결책은 “재귀(Recursion)”이다.
- 네트워크는 시퀀스의 최종 항목에 대한 출력이 이전 항목들의 재귀 함수인 형태이며, 따라서 시퀀스를 읽어가면서 점진적으로 정보를 쌓아 간다.
def recurrent_module(xs: torch.Tensor["S", "input_dims"]) -> torch.Tensor["feature_dims"]:
next_inputs = input_module(xs[-1])
next_hiddens = feature_module(recurrent_module(xs[:-1])) # recursive call
return output_module(next_inputs, next_hiddens)- 순환 신경망에서 사용하는 재귀의 특정 형태는 감소와 유사한 연산을 구현한다.
- 다른 재귀 방식이자, 차등적 이형 전형(zygohistomorphic prepromorphisms)을 위한 신경망 아키텍처
- 순환 신경망은 언어 모델링과 기계 번역에서 적절한 결과를 얻을 수 있다.
- 고전적인 LSTM부터 현대적인 GRU에 이르기까지 다양한 인기 있는 순환 구조가 있으며, 모두 거의 비슷한 기능을 가지고 있지만 일부는 더 쉽게 훈련할 수 있다.
- MLP가 “모든” feedforward 함수를 모델링할 수 있는 것과 마찬가지로, 원칙적으로 기본 RNN도 “모든” 동적 시스템을 모델링할 수 있다.
- 특히 튜링 머신을 모델링할 수 있는데, 이는 원칙적으로 컴퓨터가 할 수 있는 모든 것을 할 수 있다는 것을 공식적으로 표현한 것이다.
Why aren't we all using RNNs?
- “MLP가 모든 함수를 모델링할 수 있다”
- “RNN이 튜링 머신을 모델링할 수 있다”
- 이 두 특징은 직관력을 제공하지만 직접적으로 실용적이지는 않다.
- 무엇보다도 무작위 파라미터에서 시작하여 주어진 함수를 구현하는 파라미터를 찾을 수 있다는 학습 가능성을 보장하지 않기 때문이다.
- 신경망의 유효 용량은 기본적인 이론 및 경험적 분석에서 보이는 것보다 훨씬 낮다.
- 언어 모델링 용량을 이해하는 한 가지 방법은 촘스키 계층 구조이다.
- 이 형식 언어 모델에서 튜링 머신은 최상위에 위치한다.
- 더 나은 수학적 모델을 사용하면 촘스키 계층 구조 내에서 RNN과 LSTM은 훨씬 더 약한 것으로 나타날 수 있으며, RNN은 정규식 파서처럼 보이고 LSTM은 그 바로 위에 위치한다.
- 촘스키 계층 구조는 구문과 문법을 이해하는 데 적합하기 때문에 구문 분석기를 구축하고 공식 언어로 작업하는 데 적합하지만, 자연어 처리의 목표는 자연어를 이해하는 것이다.
- 언어를 정말로 ‘이해’한다는 것은 모호한 의미적 내용을 이해한다는 것을 의미한다.
- 언어의 모호한 의미적 내용을 다루는 데 있어 가장 중요한 것은 문법과 구문 외에도 개념 간의 확률적 관계를 모델링할 수 있는지이다.
- 이는 현재의 반복 언어 및 시퀀스 모델에 비해 이론적으로 개선의 여지를 남긴다.
Transformers are designed to train fast at scale on contemporary hardware.
- 트랜스포머 아키텍처에는 아래에서 설명하는 몇 가지 중요한 기능이 있지만, 가장 중요한 성공 요인 중 하나는 대규모로 더 쉽게 훈련할 수 있기 때문이다.
- 이러한 확장성은 아키텍처를 소개한 논문인 ‘Attention Is All You Need’에서 논의의 초점이었으며, 재귀 모델을 확장하는 것에 대한 추측이 있을 때마다 등장한다.
- RNN의 재귀는 본질적으로 순차적이고, 시퀀스 앞 출력에 의존하기 때문에 예제 내의 계산을 병렬화할 수 없다.
- 따라서 RNN은 확장하려면 예제 전체에 걸쳐 일괄 처리해야 하지만, 시퀀스 길이가 길어지면 메모리 대역폭 한계에 부딪히게 된다.
- 특히 분산 환경에서는 우수한 무작위성을 보장하면서 대규모 배치를 빠르게 제공하는 측면에서 최적화하기 어렵다.
- 반면 트랜스포머 아키텍처는 배치 간 병렬화뿐만 아니라 단일 예제 시퀀스 내에서 쉽게 병렬화할 수 있다.
- 이는 고정된 규모에서 엄청난 성능 향상을 가져올 수 있으며, 이는 더 큰 데이터셋에서 더 큰 고용량 모델을 학습할 수 있음을 의미한다.

- 원래 ‘트랜스포머’는 인코더/디코더 아키텍처이다.
- GPT 모델과 같은 대다수의 LLM은 디코더 전용인데 이는 확장성이 뛰어나기 때문이다.
- NLP에서는 언제든지 입력을 ‘출력’의 앞에 붙일 수 있다. 왜냐하면 입출력 모두 텍스트이기 때문이다.
- 그러나 우리는 여러 모달리티에서 사용할 것이므로 위와 같이 명시적인 인코더가 필요하다.
- 먼저 인코더(왼쪽)에 초점을 맞추면, 특정 위치에서의 인코딩은 이전의 모든 입력에 있어서의 함수이다.
- 하지만 인코더는 이전 인코딩들의 함수가 아니라 “한 번에” 인코딩을 생성한다.
- 디코더(오른쪽)는 이전 인코더의 “출력”을 입력으로 사용한다.
- 디코더의 출력은 네트워크에서 생성되는 레이어에서 활성화 함수를 거쳐 나온 벡터(aka embeddings)가 아니다.
softmax와argmax를 거친 후 처리된 출력이 도출된다.- 순환 아키텍처에서와 마찬가지로 임베딩을 처리하여 이러한 출력을 얻을 수 있다.
- 실제로 이것이 트랜스포머가 실행되는 한 가지 방식으로, 문자 인식을 위해 훈련할 모델,
ResnetTransformer의.forward메서드에서 일어나는 과정이다. - 다음은
ResnetTransformer의.forward메서드와.encode,.decode코드이다.
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Autoregressively produce sequences of labels from input images.
Parameters
----------
x
(B, Ch, H, W) image, where Ch == 1 or Ch == 3
Returns
-------
output_tokens
(B, Sy) with elements in [0, C-1] where C is num_classes
"""
B = x.shape[0]
S = self.max_output_length
x = self.encode(x) # (Sx, B, E)
output_tokens = (torch.ones((B, S)) * self.padding_token).type_as(x).long() # (B, Sy)
output_tokens[:, 0] = self.start_token # Set start token
for Sy in range(1, S):
y = output_tokens[:, :Sy] # (B, Sy)
output = self.decode(x, y) # (Sy, B, C)
output = torch.argmax(output, dim=-1) # (Sy, B)
output_tokens[:, Sy] = output[-1] # Set the last output token
# Early stopping of prediction loop to speed up prediction
if ((output_tokens[:, Sy] == self.end_token) | (output_tokens[:, Sy] == self.padding_token)).all():
break
# Set all tokens after end or padding token to be padding
for Sy in range(1, S):
ind = (output_tokens[:, Sy - 1] == self.end_token) | (output_tokens[:, Sy - 1] == self.padding_token)
output_tokens[ind, Sy] = self.padding_token
return output_tokens # (B, Sy)def encode(self, x: torch.Tensor) -> torch.Tensor:
"""Encode each image tensor in a batch into a sequence of embeddings.
Parameters
----------
x
(B, Ch, H, W) image, where Ch == 1 or Ch == 3
Returns
-------
(Sx, B, E) sequence of embeddings, going left-to-right, top-to-bottom from final ResNet feature maps
"""
_B, C, _H, _W = x.shape
if C == 1:
x = x.repeat(1, 3, 1, 1) # make 3 channels
x = self.resnet(x) # (B, RESNET_DIM, _H // 32, _W // 32), (B, 512, 18, 20) in the case of IAMParagraphs
x = self.encoder_projection(x) # (B, E, _H // 32, _W // 32), (B, 256, 18, 20) in the case of IAMParagraphs
# nn.Conv2d(RESNET_DIM, self.dim, kernel_size=1)
# x = x * math.sqrt(self.dim) # (B, E, _H // 32, _W // 32) # This prevented any learning
x = self.enc_pos_encoder(x) # (B, E, Ho, Wo); Ho = _H // 32, Wo = _W // 32
# PositionalEncodingImage(d_model=self.dim, max_h=self.input_dims[1], max_w=self.input_dims[2])
x = torch.flatten(x, start_dim=2) # (B, E, Ho * Wo)
x = x.permute(2, 0, 1) # (Sx, B, E); Sx = Ho * Wo
return xdef decode(self, x, y):
"""Decode a batch of encoded images x with guiding sequences y.
During autoregressive inference, the guiding sequence will be previous predictions.
During training, the guiding sequence will be the ground truth.
Parameters
----------
x
(Sx, B, E) images encoded as sequences of embeddings
y
(B, Sy) guiding sequences with elements in [0, C-1] where C is num_classes
Returns
-------
torch.Tensor
(Sy, B, C) batch of logit sequences
"""
y_padding_mask = y == self.padding_token
y = y.permute(1, 0) # (Sy, B)
y = self.embedding(y) * math.sqrt(self.dim) # (Sy, B, E)
# nn.Embedding(self.num_classes, self.dim)
y = self.dec_pos_encoder(y) # (Sy, B, E)
# PositionalEncoding(d_model=self.dim, max_len=self.max_output_length)
Sy = y.shape[0]
y_mask = self.y_mask[:Sy, :Sy].type_as(x)
output = self.transformer_decoder(
tgt=y, memory=x, tgt_mask=y_mask, tgt_key_padding_mask=y_padding_mask
) # (Sy, B, E)
# nn.TransformerDecoder(
# nn.TransformerDecoderLayer(d_model=self.dim, nhead=tf_nhead, dim_feedforward=tf_fc_dim, dropout=tf_dropout),
# num_layers=tf_layers,
# )
output = self.fc(output) # (Sy, B, C)
return output.encode메서드가 가장 먼저 실행된다.- 인코더는 원칙적으로 고정 길이 벡터의 시퀀스를 생성하는 모든 것이 될 수 있지만, 여기서는
torchvision에 구현된 ResNet을 사용한다.
- 인코더는 원칙적으로 고정 길이 벡터의 시퀀스를 생성하는 모든 것이 될 수 있지만, 여기서는
- 그런 다음 for 루프에서 시퀀스를 반복하기 시작한다.
- 지금까지의 출력에
.decode를 적용한다. - 새로운 출력이 나오면
.argmax를 적용하여 logits을 특정 토큰에 대한 구체적인 예측으로 전환한다. - 이것이 마지막 출력 토큰으로 추가되고 루프가 다시 발생한다.
- 이러한 방식으로 실행되는 모델은 자체 출력에서 모델을 호출하여 다음 값을 생성하는 순환 아키텍처와 매우 유사하다.
- 이러한 유형의 모델을 자동 회귀 모델이라고도 하는데, 회귀 모델에서와 마찬가지로 자체 출력을 기반으로 다음 값을 예측하기 때문이다.
- 하지만 트랜스포머는 RNN보다 더 확장성 있게 학습되도록 설계된 것이지 반드시 더 확장성 있게 추론을 실행하도록 설계된 것은 아니며, 실제로 학습 중에 모델의
.forward가 호출되는 경우도 없다. - 트랜스포머 모델을 훈련하는 데 사용하는
LightningModule의training_step, 즉TransformerLitModel을 확인하여 훈련 중에 어떤 일이 일어나는지 살펴보자. - 다음은
TransformerLitModel의.training_step메서드이다.
def training_step(self, batch, batch_idx):
x, y = batch
logits = self.teacher_forward(x, y[:, :-1])
loss = self.loss_fn(logits, y[:, 1:])
self.log("train/loss", loss)
outputs = {"loss": loss}
return outputs- 입력에
model.forward대신.teacher_forward를 호출하는 것을 알 수 있다. .teacher_forward을 살펴보자.
def teacher_forward(self, x: torch.Tensor, y: torch.Tensor) -> torch.Tensor:
"""Uses provided sequence y as guide for non-autoregressive encoding-decoding of x.
Parameters
----------
x
Batch of images to be encoded. See self.model.encode for shape information.
y
Batch of ground truth output sequences.
Returns
-------
torch.Tensor
(B, C, Sy) logits
"""
x = self.model.encode(x)
output = self.model.decode(x, y) # (Sy, B, C)
return output.permute(1, 2, 0) # (B, C, Sy)- 이 함수는 입력 x와 기준점 타깃 y를 모두 사용하여 출력을 생성한다.
- 이를 “teacher forcing”이라고 한다.
- “teacher” 신호는 모델이 정답을 맞힌 것처럼 행동하도록 “forcing(강제)”하는 것이다.
- teacher forcing은 원래 RNN을 위해 개발되었다.
- RNN에서 가장 적합한 teacher 신호는 우리가 알지 못하는 타겟 임베딩 벡터인 반면, 우리의 네트워크에 적합한 teacher 신호는 학습 중에 접근할 수 있는 타겟 데이터이기 때문에 더 효과적이다.
- 추론 중에 실측 데이터(ground truth)에 액세스할 수 없는 경우 자동 회귀
.forward메서드로 되돌아간다. - 이 ‘트릭’을 통해 트랜스포머 아키텍처는 인터넷 규모의 데이터셋을 최대한 활용하는 데 필요한 파라미터 수에 맞춰 모델을 쉽게 확장할 수 있다.
Is there more to Transformers more than just a training trick?
- 초대형 트랜스포머 모델은 포토리얼리즘적인 고해상도 이미지 생성 등 머신 러닝 분야에서 가장 최근의 흥미로운 결과를 이끌어냈다
- 트랜스포머의 기본 아키텍처는 고밀도 행렬 곱셈과 비선형성의 조합일 뿐이며, 컨볼루션 아키텍처보다 더 단순할 수도 있다.
- 그리고 2017년 트랜스포머 도입 이후 발전은 주로 더 정교한 모델 아키텍처를 만드는 것이 아니라 기본 아키텍처의 규모를 늘리거나 인코더를 삭제하는 GPT 모델처럼 더 단순하게 만드는 방식으로 이루어졌다.
- 이러한 모델은 또한 매우 간단한 작업으로 학습된다.
- 대부분의 LLM은 이전 요소가 주어졌을 때 시퀀스의 다음 요소를 예측하는 간단한 작업이다.
- 이러한 작업은 웹 스크래핑 등을 통해 대규모 데이터셋을 쉽게 얻을 수 있기 때문에 선택된다.
- 가장 기본적인 최적화 문제를 위해 고안된 1차 테일러 근사 기법을 활용한 확률론적 최적화 기법(e.g. SGD, Adam)은 다른 최적화 영역에 있어서 지배적인 2차 테일러 근사법에 기반한 최적화 기법보다 더 쉽고 간단하게 확장성 있는 방식으로 훈련된다.
- 확장성이 뛰어나고 세부 구현에 견고하지만 단순하고 낭비적으로 보이는 아키텍처가 더 영리하지만 확장하기 어려운 까다로운 접근 방식을 능가한다는 것이 ML 업계에서 얻은 씁쓸한 교훈이다.
- 이 교훈을 바탕으로 일부 사람들은 머신러닝, 나아가 인공지능에 있어서도 확장성만 있으면 된다고 주장한다.
- 물론 알고리즘이 비교적 간단하기 때문에 이 정도 규모로 모델을 학습시키는 것이 쉽다는 말은 아니다.
- 데이터셋에는 데이터 클리닝이 필요하, 모델 아키텍처에는 튜닝과 하이퍼파라미터 선택이 필요하며, 분산된 시스템에는 관리와 공급이 필요하다.
- 그러나 모든 단계에서 가장 간단한 알고리즘을 선택하면 확장 문제를 해결할 수 있다.
- 확장성의 중요성은 이론적 고려 사항이나 구현 세부 사항보다 훨씬 더 중요한 트랜스포머 아키텍처의 핵심이다.
- 즉, 이러한 대형 트랜스포머 모델은 인상적인 동작을 수행할 수 있으며 이러한 동작을 달성하는 방법을 이해하는 것은 지적 흥미를 위한 것일 뿐이다.
- 또한 다른 아키텍처와 마찬가지로 모델과 모델의 사용자에게 있어서 고려해야 할 일반적인 failure mode가 있다.
- 아래에서는 트랜스포머에 대한 두 가지 핵심 직관을 다루겠습니다
- 트랜스포머는 ResNet과 같이 잔여적(residual)이며,
- 저차원의 시퀀스 변환을 구성한다.
- 즉, 트랜스포머는 일련의 간단한 명령어를 통해 “테이프(tape)” 또는 메모리를 읽고 쓰는 컴퓨터와 비슷하게 작동한다.
- 시퀀스 모델링에 일반적으로 사용되지만 기본적으로 이 아키텍처는 위치에 민감하지 않은(position insensitive) 놀라운 구현 세부 사항도 다룰 것이다.
Intuition #1: Transformers are highly residual.
- 이러한 직관에 대한 논의는 AI 안전 및 연구 회사인 Anthropic의 'A Mathematical Framework for Transformer Circuits'에서 논의된 내용을 요약한 것이다. (아래 그림은 해당 블로그 게시물에서 가져온 것이다.)
- 트랜스포머를 진정으로 이해하고 싶다면 관련 연습 문제를 포함하고 있는 이 글을 확인해 보기를 권장한다.
- 이름만 봐도 ResNet이 잔여적이라는 것을 알 수 있다.
- 하지만 어떤 의미에서 트랜스포머는 ResNet보다 잔차 계산과 훨씬 더 밀접하게 연관되어 있다.
- ResNet 및 관련 아키텍처에는 다운샘플링이 포함되므로 입력에서 출력으로 직접 연결되는 경로가 없다.
- 트랜스포머에서는 토큰이 임베드되는 순간부터 수십 또는 수백 개의 중간 레이어를 거쳐 클래스 logit에 “unembedded” 될 때까지 정확히 동일한 모양이 유지된다.
- 트랜스포머 Circuit의 작성자는 이 경로를 “residual stream”이라고 부른다.
- residual stream은 관점을 바꾸면 쉽게 이해할 수 있는데, 텐서에 작용하는 레이어가 강조된 기존 아키텍처 다이어그램 대신, 레이어를 통과하는 텐서를 강조하는 아래 이미지를 고려하자.

- 변수 및 용어에 대한 정의는 표기법 사이트를 참조하자.
- 이것은 디코더 전용 트랜스포머 아키텍처이므로 위의 원본 아키텍처 다이어그램의 오른쪽 부분과 비교해야 한다.
- attention 블록과 MLP 레이어의 출력은 ResNet에서와 같이 입력에 추가되는 것을 확인할 수 있다.
- 이러한 연산은 기존 트랜스포머 다이어그램에서 “Add & Norm” 레이어로 표시되며, 여기서는 단순화를 위해 정규화는 무시한다.
- 잔차 연산에 대한 이러한 총체적인 노력은 임베딩의 크기(”모델 차원” 또는 “임베딩 차원”, 그리고 아래 코드에 등장할
d_model)가 전체 네트워크에 걸쳐 동일하게 유지됨을 의미한다. - 예를 들어, 각 레이어의 출력은 logit을 생성하는 “unembedding” 레이어에 대한 입력으로 사용될 수 있다.
- 중간 레이어의 계산을 unembedding 레이어에 전달하고 logit 텐서를 검사하는 것만으로 중간 레이어의 계산을 읽어낼 수 있다.
- 자세한 실험과 대화형 노트북은 "interpreting GPT: the logit lens"를 참조.
- 간단히 말해, 네트워크를 통해 임베딩이 깊이 있게 진행됨에 따라 다음 토큰 예측이 일종의 “점진적으로 개선”되는 것을 관찰할 수 있다.
Intuition #2 Transformer heads learn low rank transformations.
- 원본 논문과 대부분의 트랜스포머 프레젠테이션에서 attention 레이어는 다음과 같이 작성되어 있다.
softmax(Q⋅KT)⋅V
- (
torchtyping에 기반한) PyTorch 의사 코드는 다음과 같다.
def classic_attention(
Q: torch.Tensor["d_sequence", "d_model"],
K: torch.Tensor["d_sequence", "d_model"],
V: torch.Tensor["d_sequence", "d_model"]) -> torch.Tensor["d_sequence", "d_model"]:
return torch.softmax(Q @ K.T) @ V- 구현 세부 사항(행렬 곱셈과
softmax호출을 위한bmm을 검색)을 제외하면 사실상 파이토치에서 작성된 방식과 동일하다. - 하지만 컴퓨터가 빠르게 실행할 수 있도록 연산을 작성하는 방법이 반드시 사람이 이해할 수 있도록 작성하는 가장 좋은 방법은 아니다.
- 우리가 일반적으로 레이어에 대한 “입력”이라고 생각하는 것이 표시되지 않는다.
- 대신 attention 레이어를 입력 x의 함수로 작성할 수 있다.
- 우리는 하나의 “attention head”에 대해 작성한다.
- 각 attention 레이어에는 residual stream에서 동시에 독립적으로 읽고 쓰는 여러 개의 헤드가 포함된다.
- 또한 출력 레이어 가중치 _WO_를 추가하면 다음과 같은 결과를 얻을 수 있다.
softmax(xTWTQ⏟QWKx⏟KT)xWTV⏟VWTO
- PyTorch 의사 코드는 다음과 같다.
def rewrite_attention_single_head(x: torch.Tensor["d_sequence", "d_model"]) -> torch.Tensor["d_sequence", "d_model"]:
query_weights: torch.Tensor["d_head", "d_model"] = W_Q
key_weights: torch.Tensor["d_head", "d_model"] = W_K
key_query_circuit: torch.Tensor["d_model", "d_model"] = W_Q.T @ W_K
# maps queries of residual stream to keys from residual stream, independent of position
value_weights: torch.Tensor["d_head", "d_model"] = W_V
output_weights: torch.Tensor["d_model", "d_head"] = W_O
value_output_circuit: torch.Tensor["d_model", "d_model"] = W_V.T @ W_O.T
# transformation applied to each token, regardless of position
attention_logits = x.T @ key_query_circuit @ x
attention_map: torch.Tensor["d_sequence", "d_sequence"] = torch.softmax(attention_logits)
# maps positions to positions, often very sparse
value_output: torch.Tensor["d_sequence", "d_model"] = x @ value_output_circuit
return attention_map @ value_output # transformed tokens filtered by attention mapkey_query_circuit과value_output_circuit행렬을 고려하자.- WQK:=WTQWK and WTOV:=WTVWTO
- 키/쿼리의 차원인
d_head는 모델의 차원인d_model에 비해 상대적으로 작기 때문에 WQK와 WOV는 매우 낮은 rank이며, 이는 행과 열의 수가 더 적은 두 행렬로 인수 분해된다는 말과 같다. - 이 숫자를 rank라고 한다.
- 계산할 때 이러한 행렬은 직접 계산하는 것보다 구성 요소를 통해 더 잘 표현되며, 이는 attention의 정상적인 구현으로 이어진다.
- 대규모 언어 모델에서 residual stream 차원인
d_model과 단일 헤드 차원인d_head의 비율은 보통 100:1에 달할 정도로 엄청나다. - 즉, 한 위치에서 계산되는 각 쿼리(Q), 키(K), 값(V)은 해당 위치의 residual steram에서 매우 단순하고 낮은 차원의 특징이라는 뜻이다.
- 시각적인 직관을 위해, rank가 100번째인 행렬(왼쪽)과 같은 크기의 full rank 행렬(오른쪽)을 비교해 보자.


- 첫 번째 행렬의 패턴은 두 번째 행렬의 패턴에 비해 매우 단순하다.
- low rank 변환의 또 다른 특징은 nullspace 또는 커널이 크다는 점인데, 이는 출력을 변경하지 않고 입력을 이동시킬 수 있는 방향이다.
- 즉, residual stream에 대한 많은 변화가 이 헤드의 동작에 전혀 영향을 미치지 않는다.
Residuality and low rank together make Transformers less like a sequence model and more like a computer (that we can take gradients through).
- residuality(현재 입력에 변경 사항이 추가됨)와 low rank(각 헤드에서 작은 하위 공간만 변경됨)의 조합은 트랜스포머에 대한 직관을 크게 변화시킨다.
- residual stream은 “context에 토큰을 임베딩”하는 것이 아니라, 메모리나 스크래치 패드 메모리(SPM)와 비슷해지는 것이다.
- 즉, 한 레이어가 스트림에서 작은 비트의 정보를 읽고 다시 작은 비트의 정보를 기록하는 방식이 된다.

- residual stream은 이러한 작업들이 간섭할 필요가 없을 정도로 충분히 넓기 때문에 메모리처럼 작동한다.
- 읽기 및 쓰기를 목적으로 하는 하위 공간은 주변 공간에 비해 작기 때문에 다음과 같은 이점이 있다.
- 또한 대형 모델의 경우 각 헤드의 차원은 여전히 100대이며, 고차원(>50) 벡터 공간에는 “거의 직교하는” 벡터가 많으므로 실제로는 차원보다 더 많은 자유도를 갖는다.
- 이러한 현상으로 인해 고차원 텐서는 매우 큰 콘텐츠를 처리할 수 있는 내용 주소화 연상 메모리 역할을 할 수 있다.
- 연상 메모리 주소 지정 알고리즘과 트랜스포머 attention 사이에는 밀접한 연관성이 있다.
- 즉, 초기 레이어가 이후 레이어가 사용할 수 있는 정보를 스트림에 쓸 수 있다.
- 이후 레이어는 이 정보를 수정하는 방법(e.g. 삭제를 통해 lossfmf 줄일 수 있다. 그러나 기본적으로 정보는 보존된다.)을 학습할 수 있다.

- 마지막으로, attention의 softmax는 희소화 효과가 있으며, 많은 attention 헤드가 하나의 토큰만 읽고 다른 토큰 하나에만 쓰는 경우가 많다.

- 외부 메모리에서 정보를 반복적으로 읽고 이를 사용하여 어떤 연산을 수행하고 결과를 어디에 쓸지 결정하는 것이 튜링 머신의 핵심이다.
- 구체적인 예로, 트랜스포머 Circuits work에는 일부 모델에 나타나는 “포인터 연산”의 한 형태에 대한 해부가 포함되어 있다.
- 이 관점은 트랜스포머 모델의 직관적이지 않은 수많은 특징을 설명하는 데 유망하다.
- 이 프레임워크는 트랜스포머가 정보를 쉽게 복사/붙여넣기 할 수 있는 많은 부분을 예측한다.
- 불완전하게 학습된 트랜스포머가 출력을 여러 번 반복하는 등의 현상을 설명할 수 있다.
- 또한 트랜스포머가 중간 길이의 텍스트와 Few-shot learning에서 우수한 성능을 보이는 중요한 요소인 In-context learning을 쉽게 설명할 수 있다.
- 또한 “let's think step-by-step”라는 텍스트가 입력 프롬프트에 추가되었을 때 트랜스포머는 추론 작업에서 더 나은 성능을 발휘한다.
- 이는 부분적으로는 데이터셋에서 해당 프롬프트가 더 명확한 추론과 연관되어 있고,
- 모델이 입력 후에 어떤 토큰이 나타나는 경향이 있는지 예측하도록 학습되었기에 해당 프롬프트에서 더 나은 추론을 생성하는 경향이 있기 때문이다.
- 이는 순전히 시퀀스 모델링 측면에서 설명할 수 있다.
- 또한 트랜스포머는 중간 정보를 저장하는 역할을 하는 토큰을 대량으로 생성할 수 있는 라이선스를 획득하여, 읽기 및 쓰기를 위한 residual stream을 더욱 풍부하게 만들 수 있다.
Implementation detail: Transformers are position-insensitive by default.
- attention 계산에서 각 토큰은 순서에 관계없이 서로 토큰을 쿼리할 수 있다.
- 또한 쿼리(Q), 키(K), 값(V)의 구성은 임베딩 벡터의 내용을 기반으로 하며, 이때 임베딩 벡터의 위치는 자동으로 포함되지 않는다.
- “개가 사람을 물다”와 “사람이 개를 물다”는 bag-of-words modeling에서와 같이 동일하다.
- 대부분의 시퀀스에서는 이것은 허용되지 않는다.
- 왜냐하면 절대적 위치와 상대적 위치가 중요하며 미래(나중에 등장할 토큰)를 사용하여 과거(이전에 등장한 토큰)를 예측할 수 없기 때문이다.
- 다음 토큰 예측에 사용할 수 있는 트랜스포머 아키텍처를 얻으려면 두 가지를 추가해야 한다.
- “casual(인과적)” attention은 인과 관계에 위배되는 해당 토큰으로부터 다음에 등장하는 값의 영향을 받지 않아야 한다.
- 가장 일반적인 해결책은 모든 토큰 간의 attention을 계산한 다음 인과 관계가 없는 값을 “masking(마스킹)”하여 버리는 것이다. (softmax를 적용하기 전이므로 마스킹은 -∞를 더하는 것을 의미한다.)
- 코드 베이스에서 생성된 attention 마스크 샘플 관련 코드는 아래와 같다.
from text_recognizer.models import transformer_util
attention_mask = transformer_util.generate_square_subsequent_mask(100)
ax = plt.matshow(torch.exp(attention_mask.T)); cb = plt.colorbar(ticks=[0, 1], fraction=0.05)
plt.ylabel("Can the embedding at this index"); plt.xlabel("attend to embeddings at this index?")
print(attention_mask[:10, :10].T); cb.set_ticklabels([False, True]);
- 이렇게 하면 인과관계 문제는 해결되지만 여전히 위치 정보가 없다.
- 표준 기법은 임베딩에 주파수가 증가하는 사인과 코사인을 번갈아 가며 추가하는 것이다. (회전 임베딩을 비롯한 다른 기법도 있다.)
- 그러면 시퀀스의 각 위치는 이러한 값의 패턴에서 고유하게 식별할 수 있다.
- 게다가, translation-equivariant 컨볼루션이 퓨리에 변환과 관련된 것과 같은 이유로, 변환(e.g. 상대적 위치)은 사인과 코사인의 선형 변환으로 표현하기가 매우 쉽다.
- 이러한 위치 정보를 임베딩에 덧붙인다.
- 모델이 residual이기 때문에 이 위치 정보는 기본적으로 네트워크를 통과할 때 보존되므로 반복적으로 추가할 필요가 없다.
- 코드 베이스에서 포지션 인코딩 관련 코드는 아래와 같다.
PositionalEncoder = transformer_util.PositionalEncoding(d_model=50, dropout=0.0, max_len=200)
pe = PositionalEncoder.pe.squeeze().T[:, :] # placing sequence dimension along the "x-axis"
ax = plt.matshow(pe); plt.colorbar(ticks=[-1, 0, 1], fraction=0.05)
plt.xlabel("sequence index"); plt.ylabel("embedding dimension"); plt.title("Positional Encoding", y=1.1)
print(pe[:4, :8])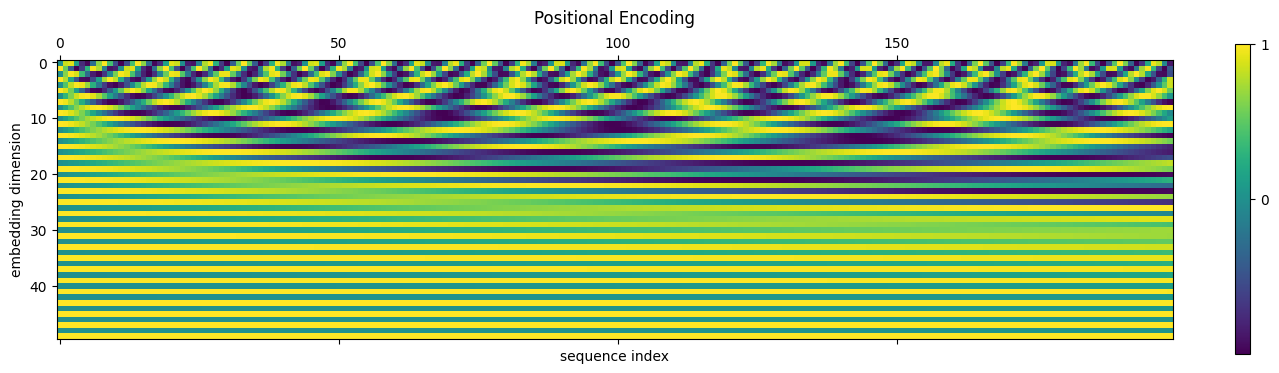
- 임베딩에 위치 정보를 추가하면 아래에서 시각적으로 확인할 수 있듯이 임베딩 정보와 위치 정보 모두 대략적으로 보존된다.
fake_embeddings = torch.randn_like(pe) * 0.5
ax = plt.matshow(fake_embeddings); plt.colorbar(ticks=torch.arange(-2, 3), fraction=0.05)
plt.xlabel("sequence index"); plt.ylabel("embedding dimension"); plt.title("Embeddings Without Positional Encoding", y=1.1)
fake_embeddings_with_pe = fake_embeddings + pe
plt.matshow(fake_embeddings_with_pe); plt.colorbar(ticks=torch.arange(-2, 3), fraction=0.05)
plt.xlabel("sequence index"); plt.ylabel("embedding dimension"); plt.title("Embeddings With Positional Encoding", y=1.1);

- 디코더에 공급되기 전, 평평하게 처리되는(flatten) 이미지 임베딩에 위치 정보를 통합하는 데에도 유사한 기술이 사용된다.
Learn more about Transformers
- 여기서는 트랜스포머에 대한 맛보기와 직관만 제공받을 수 있다.
- 핵심 내용을 더 잘 이해하려면 ML 연구 논문 중 놀라울 정도로 접근하기 쉬운 “Attention Is All You Need” 논문을 확인해 보자.
- 주석이 달린 트랜스포머는 원본 논문에 코드와 해설을 추가하여 훨씬 더 이해하기 쉽게 만들어 주었다.
- 더 친근하게 트랜스포머를 이해하려면 동영상과 함께 제공되는 Jay Alammar의 Illustrated Transformer를 확인해 보자.
- 위에 요약된 트랜스포머 Circuits에 대한 Anthropic의 작업은 이론적 이해를 쌓는 데 가장 좋은 자료이며 프레임워크의 확장 및 응용으로 계속 업데이트되고 있다.
- 함께 제공되는 연습 문제는 이해도를 점검하고 쌓는 데 큰 도움이 된다. (하지만 상당히 수학적인 내용이 많다.)
- 소프트웨어 엔지니어링에 대한 배경 지식이 더 풍부하다면 트랜스포머 회로의 공동 저자인 Nelson Elhage의 블로그 게시물인 Transformers for Software Engineers를 참조.
- 트랜스포머에 대한 직관력을 좀 더 부드럽게 소개하려면 Brandon Rohrer의 Transformers From Scratch 튜토리얼을 확인하자.
- 여담이지만, attention 내부의 행렬 곱셈이 트랜스포머의 대규모 런타임을 지배한다.
- 따라서 선형 시간 등 주의 메커니즘을 더 효율적으로 만들기 위해 많은 연구가 진행되었다.(리뷰 논문 참조)
- 많은 관심을 끌었음에도 불구하고, 2022년 중반에 글을 쓰는 시점에서 이러한 방법은 대규모 언어 모델에서 사용되지 않았기 때문에 트랜스포머 전문가가 아닌 이상 시간을 들여 학습할 가치가 없을 것이다.
Using Transformers to read paragraphs of text
- Lab 02b의 텍스트 인식을 위한 간단한 컨볼루션 모델은 깔끔하게 구분된 문자만 처리할 수 있었다.
- 이 모델은 이미지 위에 LeNet 스타일의 CNN을 슬라이딩하여 각 단계마다 문자를 예측하는 방식으로 작동했다.
import text_recognizer.data
emnist_lines = text_recognizer.data.EMNISTLines()
line_cnn = text_recognizer.models.LineCNNSimple(emnist_lines.config())
# for sliding, see the for loop over range(S)
line_cnn.forward??# line_cnn.forward
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Apply the LineCNN to an input image and return logits.
Parameters
----------
x
(B, C, H, W) input image with H equal to IMAGE_SIZE
Returns
-------
torch.Tensor
(B, C, S) logits, where S is the length of the sequence and C is the number of classes
S can be computed from W and CHAR_WIDTH
C is self.num_classes
"""
B, _C, H, W = x.shape
assert H == IMAGE_SIZE # Make sure we can use our CNN class
# Compute number of windows
S = math.floor((W - self.WW) / self.WS + 1)
# NOTE: type_as properly sets device
activations = torch.zeros((B, self.num_classes, S)).type_as(x)
for s in range(S):
start_w = self.WS * s
end_w = start_w + self.WW
window = x[:, :, :, start_w:end_w] # -> (B, C, H, self.WW)
activations[:, :, s] = self.cnn(window)
if self.limit_output_length:
# S might not match ground truth, so let's only take enough activations as are expected
activations = activations[:, :, : self.output_length]
return activations- 하지만 안타깝게도 손글씨 텍스트는 동일한 크기의 깔끔하게 구분된 문자로 제공되지 않기 때문에 해당 모델과 함께 작동하도록 설계된 합성 데이터로 모델을 학습시켰다.
- 이제 더 나은 모델을 갖게 되었으므로 더 나은 데이터, 즉 IAM 손글씨 데이터베이스로 작업할 수 있다.
- 아래 코드는
LightningDataModule을 사용하여 이 데이터를 다운로드하고 사전 처리하여 결과를 디스크에 기록하는 코드이다. - 그런 다음
DataLoader를 가동하여 배치를 제공할 수 있다. - 상용 머신에서 처음 실행하는 데는 몇 분이 걸릴 수 있으며, 대부분의 시간은 데이터를 추출하는 데 소요된다.
- 이후 실행 시에는 시간이 많이 걸리는 작업이 반복되지 않는다.
iam_paragraphs = text_recognizer.data.IAMParagraphs()
iam_paragraphs.prepare_data()
iam_paragraphs.setup()
xs, ys = next(iter(iam_paragraphs.val_dataloader()))
iam_paragraphs- 이제 배치가 완성되었으니 몇 가지 샘플을 살펴보자.
import random
import numpy as np
import wandb
def show(y):
y = y.detach().cpu() # bring back from accelerator if it's being used
return "".join(np.array(iam_paragraphs.mapping)[y]).replace("<P>", "")
idx = random.randint(0, len(xs))
print(show(ys[idx]))
wandb.Image(xs[idx]).image<S>The second said that the problems which arise from the comparisons with
the Synoptics can be reasonably solved by paying due regard to the time and
plan and to the different public for which, or against which, the author wrote.
The third article excluded any allegorical interpretation of the Gospel.<E>
.config를 전달하면 이 데이터에서ResnetTransformer모델을 실행할 수 있다.
import text_recognizer.models
rnt = text_recognizer.models.ResnetTransformer(data_config=iam_paragraphs.config())- 이제 모델이 충분히 커져서 단일 입력으로 작업할 때에도 GPU 가속을 최대한 활용해야 하므로 GPU가 있으면 GPU로 캐스팅한다.
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
rnt.to(device); xs = xs.to(device); ys = ys.to(device);- 먼저 ResNet 인코더를 통과시켜 보자.
resnet_embedding, = rnt.resnet(xs[idx:idx+1].repeat(1, 3, 1, 1))
# resnet is designed for RGB images, so we replicate the input across channels 3 timesresnet_idx = random.randint(0, len(resnet_embedding)) # re-execute to view a different channel
plt.matshow(resnet_embedding[resnet_idx].detach().cpu(), cmap="Greys_r");
plt.axis("off"); plt.colorbar(fraction=0.05);
- 이러한 임베딩은 훈련되지 않은 무작위 가중치에 의해 생성되었으며, unembedding/판독 레이어를 훈련시켜야만 합리적인 텍스트를 얻을 수 있다.
preds, = rnt(xs[idx:idx+1]) # can take up to two minutes on a CPU. Transformers ❤️ GPUs
print(show(preds.cpu()))<S>?xpSG
AAx//SpxAV/A///p/p"V/U4m////!pA"////!4/p/p4VdA//!//S//AESV&dpp4UAd
<S>A
/pp/VGp"UU/!GASA/"!AU/!"d//xx/p/pdmASk/!4d!SA+Ax!A!- Teacher forcing이 없으면 런타임도 반복마다 가변적이며, 모델은 드롭아웃 레이어 덕분에 결정적이지 않은 “종료 시퀀스” 또는 패딩 토큰을 생성할 때 멈춘다.
- 비슷한 이유로 런타임은 입력에 따라 가변적이다.
- 자동 회귀 생성의 가변적인 런타임은 확장에도 좋지 않다.
- 대규모 확장에 필요한 분산 환경에서는 forward를 여러 디바이스에서 동기화해야 하며, 한 디바이스에서 훨씬 긴 시퀀스 배치를 생성하면 다른 디바이스가 완료될 때까지 기다리는 동안 다른 모든 디바이스가 유휴 상태가 된다.
- 모델을
TransformerLitModel으로 바꿔서 teacher forcing을 실행해 보자.- 왜 파이토치 모듈의 일부에 teacher forcing이 적용되지 않는지 궁금할 수 있는데,
- 일반적으로 train, validation 및 test에는 필요하지만 추론에는 필요하지 않은 것들을
LightningModule에 캡슐화해야 한다. - teacher forcing은 트랜스포머를 강력하게 만드는 데 매우 중요하지만, 이 패러다임에 적합하다.
import text_recognizer.lit_models
lit_rnt = text_recognizer.lit_models.TransformerLitModel(rnt)- 이제 대상
ys도 제공하면.teacher_forward를 사용할 수 있다.
forcing_outs, = lit_rnt.teacher_forward(xs[idx:idx+1], ys[idx:idx+1])- 생성물은 항상 가능한 최대 길이이지만 런타임과 출력 길이는 결정론적이고 일정하기 때문에
rnt.forward보다 빠르게 실행되지 않을 수 있다. - Teacher forcing을 적용한다고 해서 예측이 반드시 더 좋아지는 것은 아니다.
- 여전히 반복적이고 의미 없는 결과이다.
forcing_preds = torch.argmax(forcing_outs, dim=0)
print(show(forcing_preds.cpu()))+L/<S>/ApC!pxf"//pd4pS"SxU!E&dAV4xxxx//dpfADpddEE/pAGp/U!p/d//!VxA/x4S4/pp/!xdG//xp"dVAUVVf///p//!/cAA/?/Vcpld/AU//px/pU/pd<S>f!EdGd/f/!f/Vc"d//xpppGUpx/S/Gxddddd/SVxA/x/EA//U/5/AA///c"4/dpa!Ac!&A
AC/f/c/x+/fc/AxG/xxpxpAAxxU!f/V!4cpA"/X4pdppAxp/lEV?/p//
/4Uf/AAUA/lD/c/
px""VA
/
U/"//Uf//+<S>9l/4///p/5p/x/A"f?!A!AUA/?!d/p/!!?p?c"///U/"//4/foDS!p/AS/x?w4+d////"'/AUpA//xAUp///Spp"/mU&Ad
US/d"A/d/A/!.pf/U&/U.!fS6"6<S>+!SN/x'/p/pSdd/!!S/UU'/S!dl'"d/E?SSSAppUAS/?dS.pSU/'9/wdU?S44!U/!4pV/ppL/S!A4!!/p/p!CU?/Apd/UUSC+/!A////4Cp//d?Afo!x//U//Ll/"dd/AV/xU.?UU/UAA
cfpUllAU/p&//AUyp
!?d/daf/!!A!"fSdV//UpVd/df/dpp/9dSxSCpAp/9Sdp//d//SAUVA/x/V/!xE?S/JpS/A/x/S/p4U9!U/!l//?p!UA/p
&&fplTraining the ResNetTransformer
- 드디어 손으로 쓴 텍스트의 전체 단락에 대해 이 모델을 훈련할 준비가 되었다.
- 이 모델은 배포된 텍스트 인식기 애플리케이션에서 사용하는 모델이다.
- 지금까지 살펴본 모델보다 훨씬 더 크기 때문에 사용 가능한 컴퓨팅 리소스, 특히 GPU 메모리를 쉽게 능가할 수 있다.
- 이를 위해 자동 혼합 정밀도를 사용하여 대부분의 부동 소수점 크기를 절반으로 줄임으로써 메모리 소비를 줄이고 계산 속도를 높일 수 있다.
- GPU의 사용 가능한 RAM이 8GB 미만인 경우 “CUDA 메모리 부족” 런타임 오류(
RuntimeError)가 표시된다. - 이 경우
--batch_size를 줄여서 해결할 수 있다.
import torch
gpus = int(torch.cuda.is_available())
if gpus:
!nvidia-smi
else:
print("watch out! working with this model on a typical CPU is not feasible")- Tesla P100과 같이 괜찮은 GPU를 사용하더라도 한 번의 훈련을 실행하는 데 10분 이상 걸릴 수 있다.
- 런타임을 짧게 유지하기 위해
--limit_{train/val/test}_batches플래그를 사용하지만, 이 플래그를 제거하면 전체 훈련이 어떻게 되는지 확인할 수 있다. - 이 모델을 단일 GPU에서 적절한 성능으로 훈련하는 데는 하룻밤 이상 오랜 시간이 걸릴 수 있다.
- 2022년 중반 시점에서 이 코드베이스로 이 데이터셋에서 이 모델을 적절한 성능으로 훈련하는 데 가장 저렴한 옵션은 Lambda Lab의 GPU 클라우드에서 8xV100 인스턴스를 사용하는데 쓰이는 약 10달러 정도이다.
- 대시보드와 관련 실험을 참조.
%%time
# above %%magic times the cell, useful as a poor man's profiler
%run training/run_experiment.py --data_class IAMParagraphs --model_class ResnetTransformer --loss transformer \
--gpus={gpus} --batch_size 16 --precision 16 \
--limit_train_batches 10 --limit_test_batches 1 --limit_val_batches 2WARNING:pytorch_lightning.loggers.tensorboard:Missing logger folder: training/logs/lightning_logs
INFO:pytorch_lightning.utilities.rank_zero:Using 16bit native Automatic Mixed Precision (AMP)
INFO:pytorch_lightning.utilities.rank_zero:Trainer already configured with model summary callbacks: [<class 'pytorch_lightning.callbacks.model_summary.ModelSummary'>]. Skipping setting a default `ModelSummary` callback.
INFO:pytorch_lightning.utilities.rank_zero:GPU available: True, used: True
INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores
INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs
INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs
INFO:pytorch_lightning.utilities.rank_zero:`Trainer(limit_test_batches=1)` was configured so 1 batch will be used.
INFO:pytorch_lightning.utilities.rank_zero:IAMParagraphs.setup(fit): Loading IAM paragraph regions and lines...
INFO:pytorch_lightning.accelerators.gpu:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
INFO:pytorch_lightning.callbacks.model_summary:
| Name | Type | Params
-----------------------------------------------------------------------
0 | model | ResnetTransformer | 14.0 M
1 | model.resnet | Sequential | 11.2 M
2 | model.encoder_projection | Conv2d | 131 K
3 | model.enc_pos_encoder | PositionalEncodingImage | 0
4 | model.embedding | Embedding | 21.5 K
5 | model.fc | Linear | 21.6 K
6 | model.dec_pos_encoder | PositionalEncoding | 0
7 | model.transformer_decoder | TransformerDecoder | 2.6 M
8 | train_acc | Accuracy | 0
9 | val_acc | Accuracy | 0
10 | test_acc | Accuracy | 0
11 | val_cer | CharacterErrorRate | 0
12 | test_cer | CharacterErrorRate | 0
13 | loss_fn | CrossEntropyLoss | 0
-----------------------------------------------------------------------
14.0 M Trainable params
0 Non-trainable params
14.0 M Total params
27.978 Total estimated model params size (MB)
/usr/local/lib/python3.10/dist-packages/pytorch_lightning/trainer/trainer.py:1927: PossibleUserWarning: The number of training batches (10) is smaller than the logging interval Trainer(log_every_n_steps=50). Set a lower value for log_every_n_steps if you want to see logs for the training epoch.
rank_zero_warn(
Epoch 0: 100%
12/12 [00:37<00:00, 3.09s/it, loss=3.59, v_num=0, validation/loss=3.580, validation/cer=1.790]
INFO:pytorch_lightning.utilities.rank_zero:Best model saved at: /content/fsdl-text-recognizer-2022-labs/lab03/training/logs/lightning_logs/version_0/epoch=0000-validation.loss=3.585-validation.cer=1.788.ckpt
INFO:pytorch_lightning.utilities.rank_zero:IAMParagraphs.setup(test): Loading IAM paragraph regions and lines...
INFO:pytorch_lightning.utilities.rank_zero:Restoring states from the checkpoint path at /content/fsdl-text-recognizer-2022-labs/lab03/training/logs/lightning_logs/version_0/epoch=0000-validation.loss=3.585-validation.cer=1.788.ckpt
INFO:pytorch_lightning.accelerators.gpu:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
INFO:pytorch_lightning.utilities.rank_zero:Loaded model weights from checkpoint at /content/fsdl-text-recognizer-2022-labs/lab03/training/logs/lightning_logs/version_0/epoch=0000-validation.loss=3.585-validation.cer=1.788.ckpt
Testing DataLoader 0: 100%
1/1 [00:17<00:00, 17.80s/it]
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Test metric ┃ DataLoader 0 ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ test/cer │ 1.7388653755187988 │
│ test/loss │ 3.4776899814605713 │
└───────────────────────────┴───────────────────────────┘
CPU times: user 1min 32s, sys: 2.95 s, total: 1min 35s
Wall time: 1min 40s
<Figure size 640x480 with 0 Axes>
'Data Science > FullStackDeepLearning' 카테고리의 다른 글
| [FSDL] Pre-Lab 02b: Training a CNN on Synthetic Handwriting Data (0) | 2023.06.26 |
|---|---|
| [FSDL] Pre-Lab 02a: PyTorch Lightning (0) | 2023.06.23 |
| [FSDL] Pre-Lab 01: Deep Neural Networks in PyTorch (0) | 2023.06.23 |